Модели организации баз данных
Иерархическая модель
Иерархическая модель базы данных состоит из объектов с указателями от родительских объектов к потомкам, соединяя вместе связанную информацию.
Иерархические базы данных могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй - объекты второго уровня и т. д.
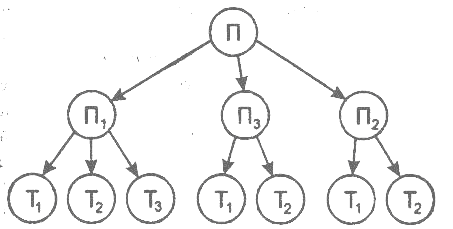
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможно, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Основное правило: никакой потомок не может существовать без своего родителя.
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект “покупатель” (родитель) и объект “заказ” (дочерний). Объект “покупатель” будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект “заказ”.
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить неиерархические данные при использовании этой модели.
Иерархической базой данных является, например, файловая система, состоящая из корневой директории, в которой имеется иерархия поддиректорий и файлов.
Сетевая модель
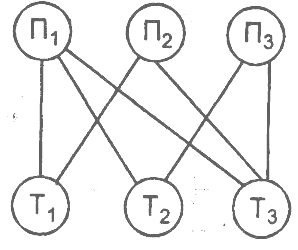
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка, в сетевой структуре данных потомок может иметь любое число предков.
В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
Реляционная модель
СУБД на основе иерархической и сетевой модели не получили широкого распространения на практике.
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношения (relation).
Реляция (от английского relation - отношение) - математический термин из теории множеств, которая легла в основу реляционной модели данных.
В реляционных базах данных вся информация сведена в таблицы, строки которых называются записями, а столбцы называются полями.
Реляционная модель данных некоторой предметной области представляет собой набор отношений, изменяющихся во времени.
Термины реляционной модели данных представлены в таблице:
| Термин реляционной модели | Эквивалентный термин |
|---|---|
Отношение |
Таблица |
Схема отношения |
Строка заголовков столбцов таблицы (заголовок таблицы) |
Кортеж |
Строка таблицы, запись |
Сущность |
Описание свойств объекта |
Атрибут |
Столбец, поле |
Домен |
Множество допустимых значений атрибута |
Первичный ключ |
Уникальный идентификатор |
Кардинальность |
Количество строк |
Степень реляции |
Количество столбцов |
Индексация |
Механизм быстрого доступа к хранящимся в таблицах данных путем их предварительной сортировки |
Транзакция |
Такое воздействие на СУБД, которое переводит ее из одного целостного состояния в другое |
Реляционная база данных представляет собой хранилище данных, содержащее набор двухмерных таблиц.
Данные в таблицах должны удовлетворять следующим принципам:
- Значения атрибутов должны быть атомарными (каждое значение, содержащееся на пересечении строки и столбца, должно быть не расчленяемым на несколько значений).
- Значения каждого атрибута должны принадлежать к одному и тому же типу.
- Каждая запись в таблице уникальна.
- Каждое поле имеет уникальное имя.
- Последовательность полей и записей в таблице не существенна.
Первичный ключ
Первичный ключ (от английского Primary Key) - минимальное множество атрибутов, являющееся подмножеством заголовка данного отношения, составное значение которых уникально определяет кортеж отношения. На практике термин первичный ключ обозначает поле (столбец) или группу полей таблицы базы данных, значение которого (или комбинация значений которых) используется в качестве уникального идентификатора записи (строки) этой таблицы.
В теории реляционных баз данных таблица представляет собой изначально неупорядоченный набор записей. Единственный способ идентифицировать определённую запись в этой таблице - это указать набор значений одного или нескольких полей, который был бы уникальным для этой записи. Отсюда и происходит понятие первичного ключа - набора полей (атрибутов, столбцов) таблицы, совокупность значений которых определена для любой записи (строки) этой таблицы и различна для любых двух записей.
Первичный ключ в таблице является базовым уникальным идентификатором для записей. Значение первичного ключа используется везде, где нужно указать на конкретную запись.
Рассмотрим отношение “Сотрудники”:
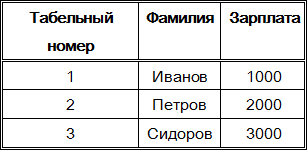
При первом взгляде на таблицу, изображающую это отношение, может показаться, что в таблице имеется три потенциальных ключа - в каждой колонке таблицы содержатся уникальные данные. Однако среди сотрудников могут быть однофамильцы и сотрудники с одинаковой зарплатой. Табельный же номер по сути свой уникален для каждого сотрудника.
Первичный ключ может состоять из единственного поля таблицы, значения которого уникальны для каждой записи. Так, например, на предприятии не может быть двух работников с одинаковыми табельными номерами, поэтому в таблице, содержащей записи о работниках, табельный номер может быть первичным ключом. Такой первичный ключ называют простым ключом.
Если таблица не имеет единственного уникального поля, первичный ключ может быть составлен из нескольких полей, совокупность значений которых гарантирует уникальность. Так, имя, фамилия, отчество, номер паспорта, серия паспорта не могут быть первичными ключами по отдельности, так как могут оказаться одинаковыми у двух и более людей. Но не бывает двух личных документов одного типа с одинаковыми серией и номером. Поэтому в таблице, содержащей записи о людях, первичным ключом может быть набор полей, состоящий из типа личного документа, его серии и номера. Такой первичный ключ называют составным ключом (от английских Compound Key, Composite Key, Concatenated Key).